
Das im Rahmen der Projekte CYWARN, emergenCITY und ATHENE entstandene Paper “A Survey on Data Augmentation for Text Classification” wurde im Journal ACM Computing Surveys (CSUR) veröffentlicht. Das Ziel des Journals, welches nach CORE als “A*” gilt und einen Impact Factor von 10.282 aufweisen kann, besteht darin, Praktikern und Forschern zu helfen, in allen Bereichen des sich schnell entwickelnden Computerwesens auf dem Laufenden zu bleiben. Computing Surveys konzentriert sich darauf, die vorhandene Literatur durch die Veröffentlichung von Überblicks- und Tutorialpaper zu integrieren und zu vertiefen.
![]()
Data Augmentation, die künstliche Erzeugung von Trainingsdaten für maschinelles Lernen durch Transformationen, ist ein weithin untersuchtes Forschungsgebiet in allen Disziplinen des maschinellen Lernens. Es ist nicht nur nützlich, um die Verallgemeinerungsfähigkeit eines Modells zu erhöhen, sondern kann auch viele andere Herausforderungen und Probleme angehen, von der Überwindung einer begrenzten Menge an Trainingsdaten über die Regularisierung bis hin zur Begrenzung der Menge an der verwendeten Daten zum Schutz der Privatsphäre. Ausgehend von einer genauen Beschreibung der Ziele und Anwendungen der Datenerweiterung und einer Taxonomie für bestehende Arbeiten befasst sich dieses Übersichtspaper mit Datenerweiterungsmethoden für die Textklassifikation und soll Forschern und Praktikern einen prägnanten und umfassenden Überblick geben.
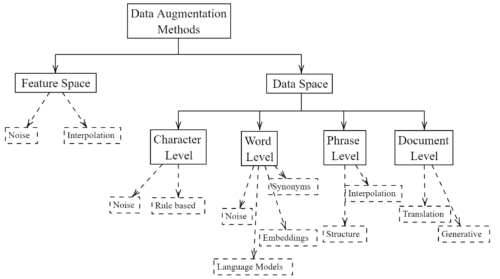 Ausgehend von der Taxonomie werden in dem Paper mehr als 100 Methoden in 12 verschiedene Gruppen eingeteilt und Hinweise auf den Stand der Forschung gegeben, indem aufgezeigt wird, welche Methoden vielversprechend sind und wie diese im Kontext zueinander stehen. Schließlich werden Forschungsperspektiven aufgezeigt, die einen Baustein für künftige Arbeiten darstellen können.
Ausgehend von der Taxonomie werden in dem Paper mehr als 100 Methoden in 12 verschiedene Gruppen eingeteilt und Hinweise auf den Stand der Forschung gegeben, indem aufgezeigt wird, welche Methoden vielversprechend sind und wie diese im Kontext zueinander stehen. Schließlich werden Forschungsperspektiven aufgezeigt, die einen Baustein für künftige Arbeiten darstellen können.
Die Berechnungen für das Forschungsvorhaben wurden auf dem Lichtenberg-Hochleistungsrechner der TU Darmstadt durchgeführt.
Das Paper finden Sie hier:
Survey on Data Augmentation for Text Classification
ACM Computing Surveys (CSUR) . doi:10.1145/3544558
[BibTeX] [Abstract] [Download PDF]